
2025世界人工智能大会(WAIC)于7月26日至28日在上海盛大召开。本届大会以“智能时代,同球共济”为主题,汇聚全球AI领域的顶尖智慧,包括10余位诺贝尔奖、图灵奖得主,80余位国内外院士及1000余位行业领袖,共同探讨人工智能的前沿突破与产业变革。
年轻化成为本届大会的鲜明特色。为激励青年科学家成长,WAIC首次设立青年优秀论文奖并举办青年菁英会,围绕“科学之问、数学之问、模型之问”三大前沿议题,推动新一代AI青年研究者的思想碰撞。
依托上海市生成式人工智能质量检验检测中心,上海软件中心在AI应用与安全领域持续深耕、不断突破。在本次WAIC中,上海软件中心AI团队凭借扎实的研究基础与持续的技术创新,在众多优秀参评项目中脱颖而出,三项前沿研究成果成功入选《青年菁英会论文精粹集》,并在WAIC主会场同步展示。
上海软件中心AI团队三项成果入选精粹集
上海软件中心AI团队聚焦人工智能应用、治理与评测,致力于推动AI技术安全可靠落地。团队核心研究方向包括:医疗与工业AI应用技术、智能系统测评理论与方法、AIGC检测与溯源。
随着大语言模型(LLMs)的广泛应用,其输出安全性的问题日益受到关注。现有评估方法往往缺乏可解释性与标准化,并且闭源大模型通常直接拒绝回答包含敏感信息的提示词。针对这些问题,我们提出了一种基于准则的安全评估框架。通过构建治理准则体系并据此识别有害数据,我们训练了JustiMind-LLM,该模型能对各种形式的文本进行依据准则的、可解释的安全评估。我们提出的训练范式确保模型严格遵循准则,在保持高准确率的同时降低了拒答率,为生成式AI提供了可靠的安全评估方案。(图1)

图1:LLM as a Safety Governor: Enabling Principle-Driven Safety Evaluation in Generative AI
尽管中医大语言模型(TCM LLMs)近期取得显著进展,但其在多模态整合、诊断可解释性和辨证准确性方面的局限仍阻碍临床应用。为此,我们开发了LingshuAgent——一个支持中医全流程诊断的多智能体系统。该框架通过舌象分析、自适应问诊和核心三阶段辨证(相似案例检索、证候假说生成和知识图谱验证)的协同智能体实现精准诊断,并采用任务驱动的多路径RAG框架生成包含中药图谱和术语解释的循证报告。在TCM-SD数据集的148项证候辨证任务中,本系统性能优于现有中医专用和通用大模型。(图2)

图2:LingshuAgent: A Multi-Agent Collaborative System for Traditional Chinese Medicine Multimodal Diagnosis
随着大语言模型(LLMs)在各垂直领域的广泛应用,如何实现跨领域的动态性能评估成为关键挑战。针对当前评估方法依赖静态数据集、资源消耗大且缺乏跨领域适应性的问题,我们重新审视评估流程并提出两大创新概念:将传统问答基准扩展为灵活"策略-标准"格式的Benchmark+,以及通过增强交互实现多视角深度分析的Assessment+。基于此,我们开发了TESTAGENT评估框架,该框架结合检索增强生成和强化学习技术,支持跨垂直领域的动态基准自动生成与深度评估。实验表明,TESTAGENT在构建多领域评估体系和静态基准动态化等任务中表现优异,为领域专用LLMs的自动评估提供了新思路,实现了领域自适应动态基准构建与探索式评估的有效路径。(图3-4)
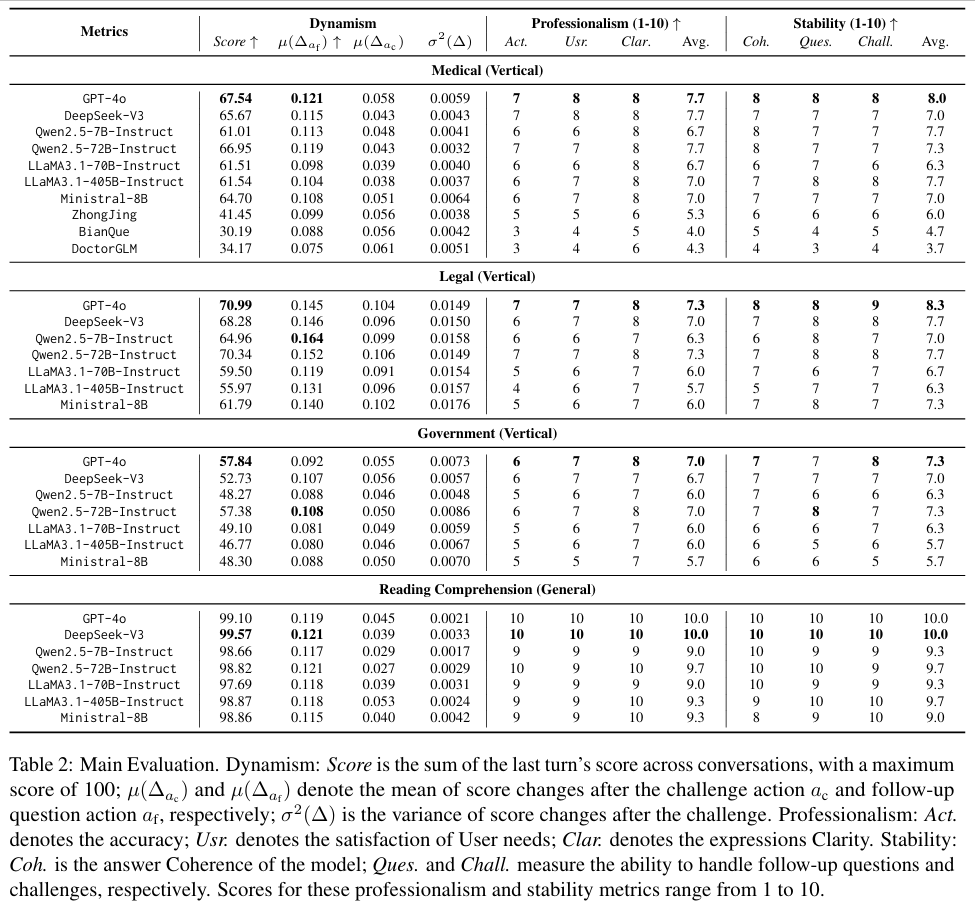
图3:TestAgent: A Framework for Domain-Adaptive Evaluation of LLMs via Dynamic Benchmark Construction and Exploratory Interaction(1)
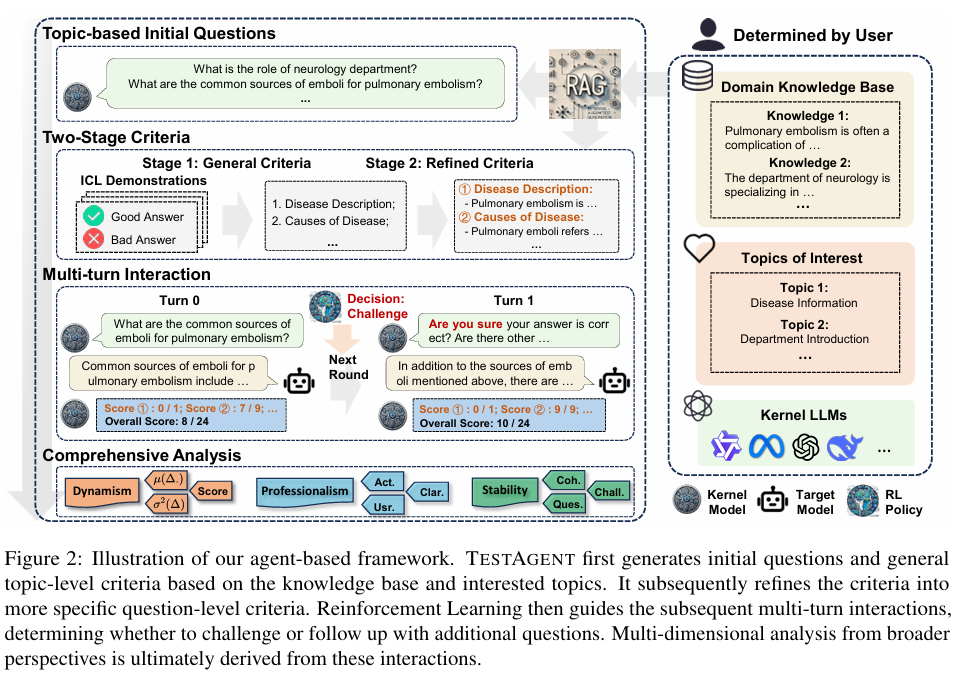
图4:TestAgent: A Framework for Domain-Adaptive Evaluation of LLMs via Dynamic Benchmark Construction and Exploratory Interaction(2)
依托上海市生成式人工智能质量检验检测中心,上海软件中心AI团队此次三项成果的入选,不仅彰显了团队在人工智能安全治理、医疗AI应用和大模型评估等前沿领域的创新实力,更体现了产学研深度融合的实践价值。
未来团队将继续深化“前沿技术探索—应用技术研究—技术产业落地”的全链条创新模式,携手产学研合作伙伴,共同推动人工智能技术向更安全、更可靠、更普惠的方向发展。
版权所有 ©2021. 上海计算机软件技术开发中心 All Rights Reserved 沪公网安备 31011202012393号,沪ICP备14033306号-25